

Introduction to Database Management System


Database Management Systems (DBMS) are software systems used to store, retrieve, and run queries on data. Before studying DBMS we should know what exactly is this data and how it is different from the information.
Data: Data is an unprocessed set of inputs, which is not self-explanatory.
Information: Information is the processed form of data.
Software Applications that utilize data are relied upon to meet a few necessities of end-users. Let us take the example of a Facebook application.

Data is stored in flat files and can be accessed using any programming language. The file-based approach suffers following problems:
Dependency of the program on the physical structure of the data
Complex process to fetch data
Loss of data on simultaneous access
Inability to give access based on record (Security)
Data redundancy
Database vs DBMS
A Database is a shared collection of logically related data and a description of these data, designed to meet the information needs of an organization.
A Database Management System(DBMS) is a software system that enables users to define, create, maintain, and control access to the database. Database Systems typically have high costs and require high-end hardware configurations.
Types of Database System
Database systems are categorized into four types based on the underlying structure used to store data. These database systems in chronological order of their evolution are Hierarchical, Network, Relational and NoSql.
Hierarchical Database: Hierarchical Databases organize data into a tree-like structure. Data is stored as records that are connected through parent-child relationships. Some examples of Hierarchical Databases are Information Management System (IMS), Raima Database Manager (RDM) Mobile etc.
Network Database: Network Databases organize data into a graph structure in which object types are nodes and relationship types are arcs. Each record can have multiple parent and child records. Some examples of Network Databases are Integrated Database Management Systems (IDMS), Integrated Data Stores (IDS) etc.
Relational Database: Relational Databases organize data into one or more tables. A table consists of attributes (columns), and tuples (rows) and provides a way to uniquely identify each tuple. Tables are related to each other through parent-child relationships. Some examples of Relational Databases are DB2, Oracle, SQL Server etc.
NoSQL Database: NoSQL (Not only SQL) database uses key-value, graph or document data structures to store data. These databases aim for simplicity of design, horizontal scaling and finer control over availability. Some examples of No SQL databases are Cassandra, MongoDB, CouchDB, OrientDB, HBASE etc.
Component of a Relational Database
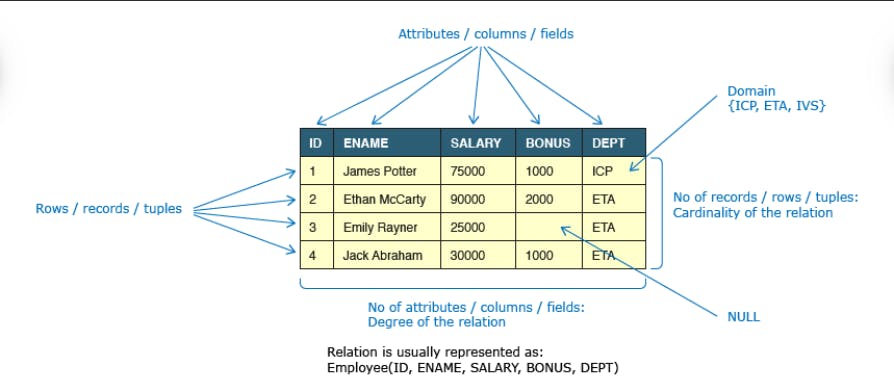
Data Integrity and Constraints
Data integrity refers to maintaining and assuring the accuracy and consistency of data over its entire life cycle. Database Systems ensure data integrity through constraints which are used to restrict data that can be entered or modified in the database. Database Systems offer three types of integrity constraints:

Keys in DBMS
Candidate Key: A Candidate Key is a minimal set of columns/attributes that can be used to uniquely identify a single row/tuple in a relation. Candidate Keys are identified during database design, considering the basic business rules of the database. Consider the following relation about a business firm:
Employee(EmployeeNo, Name, AadharNo, Salary, DateOfBirth)
Let us try to identify some candidate keys for this relation

Thus the choice of candidate key depends upon the business context.
Primary Key: A Primary Key is the candidate key that is chosen to uniquely identify a row in a relation. The mandatory and desired attributes for a primary key are:

Let us identify the primary key from the previous example:
Employee(EmployeeNo, Name, AadharNo, Salary, DateofBirth)

When two or more columns together identify the unique row then it's referred to as Composite Primary Key. If the combination of Name and DateOfBirth is chosen as the primary key, that would be considered as a composite primary key.
Foreign Key: A Foreign Key is a set of one or more columns in the child table whose values are required to match with corresponding columns in the parent table. Foreign key establishes a relationship between these two tables. Foreign key columns identified in child tables must refer to the primary key or unique key of the parent table. The child table can contain NULL values. Let us take an example of Employee and Computer tables as given below

Computer is the parent table with COMPID as the primary key. Employee is the child table with ID as the primary key. If we need to assign a limit of one computer to an employee, then COMPID should be made the foreign key in the Employee table. It can just contain values that are available in the Computer table COMPID column or no values at all(NULL). We cannot allocate a computer that does not exist to an employee.
Additionally, numerous rows in the child table can connect to the same row of the parent table depending upon the type of relationship.